Whilst developing earlier today I encountered an issue with my environment which left me a little scared…
[17:49:36 WRN] Association to [akka.tcp://[email protected]:8081] having UID [333473583] is irrecoverably failed. UID is now quarantined and all messages to this UID will be delivered to dead letters. Remote actorsystem must be restarted to recover from this situation.
[17:49:36 INF] Shutting down remote daemon.
[17:49:36 INF] Remote daemon shut down; proceeding with flushing remote transports.
[17:49:36 WRN] Association with remote system akka.tcp://[email protected]:8081 has failed; address is now gated for 5000 ms. Reason is: [Akka.Remote.EndpointDisassociatedException: Disassociated
What was scary is the state my application was now left in.
My API continued to be responsive even though the actor system was now “dead” or should I say “must be restarted” as per the error message.
I guess this scenario is far from ideal but realistically it’s something to be expected.
At this stage I’m not entirely sure why my actor system became Disassociated but I can appreciate that network blips, bad code, GC locks might all contribute to events like these in the future.
My real issue here isn’t my actor system shutting down, it’s my API continuing to accept requests.
So how can we hook into the cluster chat to determine when I’ve been quarantined?
Terminator in my case is a simple Actor ready to receive ThisActorSystemQuarantinedEvent messages delivered to my unhealthy cluster node.
Here I’m using a small wrapper around the ActorSystem called Actors. This object gives me some control around the actor system lifecycle and I use it to invoke the CoordinatedShutdown method as recommended by the Akka.net team.
Having a teminator in your code is all well and good but we need to make sure he’s protecting our node from unwanted Cyborg attacks quarantined events.
Let’s add the following to our actor system setup.
If like me you think Serilog is pretty fantastic then you might have wanted to extend your implementation with custom enrichers.
Below are a couple templates you can use to dynamically enrich your logs with whatever properties you need.
In my example I’m enriching my logs with the property ReleaseNumber given the environment variable RELEASE_NUMBER.
1. Create the log event enricher
This is the real meat when it comes to creating a custom Serilog enricher. The two important aspects are setting a constant PropertyName value
and providing a means to resolve the value of that property.
publicclassReleaseNumberEnricher:ILogEventEnricher{LogEventProperty_cachedProperty;publicconststringPropertyName="ReleaseNumber";/// <summary>/// Enrich the log event./// </summary>/// <param name="logEvent">The log event to enrich.</param>/// <param name="propertyFactory">Factory for creating new properties to add to the event.</param>publicvoidEnrich(LogEventlogEvent,ILogEventPropertyFactorypropertyFactory){logEvent.AddPropertyIfAbsent(GetLogEventProperty(propertyFactory));}privateLogEventPropertyGetLogEventProperty(ILogEventPropertyFactorypropertyFactory){// Don't care about thread-safety, in the worst case the field gets overwritten and one property will be GCedif(_cachedProperty==null)_cachedProperty=CreateProperty(propertyFactory);return_cachedProperty;}// Qualify as uncommon-path[MethodImpl(MethodImplOptions.NoInlining)]privatestaticLogEventPropertyCreateProperty(ILogEventPropertyFactorypropertyFactory){varvalue=Environment.GetEnvironmentVariable("RELEASE_NUMBER")??"local";returnpropertyFactory.CreateProperty(PropertyName,value);}}
2. Provide a means to add your enricher to your logger configuration
The alternative way is to import your enricher using an appsettings.json file using the Serilog.Settings.Configuration package.
This package will scan all assemblies listed in the Using property (as well as any assemblies belonging to the Serilog namespace)
for methods extending the LoggerEnrichmentConfiguration object.
If your enricher isn’t being applied then double check the Using property
matches the dll where your extension method resides.
Today I came across a really annoying issue which practically wiped out my whole day! >.<
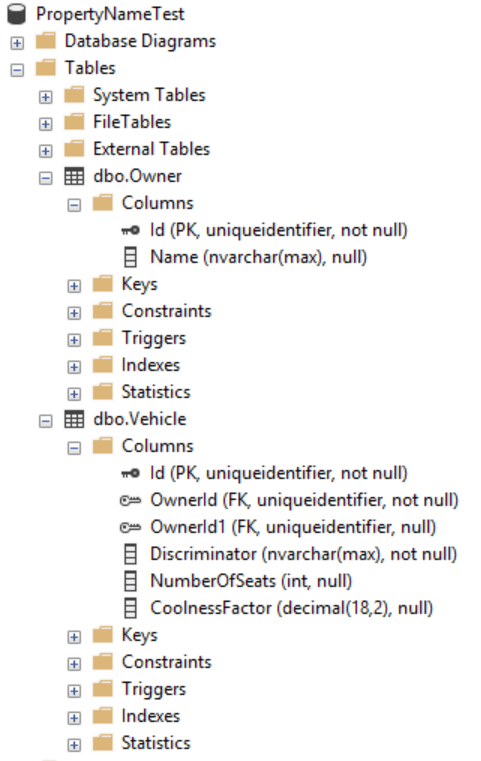
I was undertaking an ambitious project whereby I’d map some pre-existing SQL tables to a new set of domain classes when I came across the following error…
System.Data.SqlClient.SqlException : Invalid column name 'OwnerId1'.
at System.Data.SqlClient.SqlCommand.<>c.<ExecuteDbDataReaderAsync>b__180_0(Task`1 result)
at System.Threading.Tasks.ContinuationResultTaskFromResultTask`2.InnerInvoke()
at System.Threading.Tasks.Task.Execute()
For some context the domain classes I wrote were abstract with navigation properties on both the abstract classes, as well as the derrived classes.
To save your sanity I have recreated a very basic similar set of classes for your eye balls.
In fact digging into the EntityTypeBuilder source code explicity outlines this case.
Summary:
Configures a relationship where this entity type has a reference that points
to a single instance of the other type in the relationship.
Note that calling this method with no parameters will explicitly configure this
side of the relationship to use no navigation property, even if such a property
exists on the entity type. If the navigation property is to be used, then it
must be specified.
I’m not 100% sure why the navigation expression defaults to null but hey ho.
I’m a really big fan of the new slim csproj files but bundled in with this super sleek XML markup is a sneaky change
to the way NuGet packages are loaded.
You’ll probably start by noticing that the dreaded packages.config file has disappeared! Hooray!
Personally I had always taken issue with this file. The amount of times I’d seen my team use the Visual Studio NuGet GUI
tool and inadvertently install a plethora of unintended packages was frightening.
Part of me doesn’t blame them. While the command line syntax isn’t particilarly difficult, it doesn’t seem to be encouraged
and is rarely spoken of highly.
The replacement is the <PackageReference /> section of your csproj file.
I feel this is a much nicer way of working and really lowers the barrier to entry for developers.
I particularly like the way your packages are restored on save. I’ve already witnessed my team opting to modify their csproj
files to include packages, check versions and references over using the GUI tool.
But for all this nice stuff one thing seemed a little odd.
Why aren’t my NuGet packages restoring to my Packages folder?
Packages are now restored to %USERPROFILE%\.nuget\packages.
I guess the reasoning behind this makes sence. I mean, why do you need to have multiple copies of the same packages
across your development machine?
Maybe I’ve just been burned too many times in the past but I sort of got to like the local /Packages cache. The exercise
of deleting your /bin, /obj and /Packages folders when something’s playing up becomes that little bit more difficult.
Turns out you can restore this functionality if you wish to. If you’re familiar with nuget.config files then you’ll be
pleased to hear it’s as simple as adding the new config key globalPackagesFolder to the <config> section.
For those of you who aren’t, the nuget.config file is a simple file you can place along side your *.sln file to
specify a number of configuration for your team project.
The below file will restore packages from both the old packages.config and the new <PackageReference /> formats to
your .sln file’s parent directory (when placed along side your .sln file).
Today I had my devops hat on and got to work with Visual Studio Team Services automated builds.
I was really hoping that the default Hosted VS2017 build agent had a copy of SQL Server or SQL Express installed
so that my integration test library would be able to deploy and execute a number of tests.
ERROR
System.Data.SqlClient.SqlException : Connection Timeout Expired. The timeout period elapsed while attempting to consume the pre-login handshake acknowledgement. This could be because the pre-login handshake failed or the server was unable to respond back in time. The duration spent while attempting to connect to this server was - [Pre-Login] initialization=141279; handshake=79;
System.ComponentModel.Win32Exception : The wait operation timed out
After a moment of despair and a frantic Google I sussed that SQL Express should indeed be installed, so why the Connection Timeout?
Turns out SQL Express isnt always started when your build agent starts.
I managed to fix this by introducing a PowerShell step into my VSTS Build Definition.
This one caught me out today and it took a little while to diagnose the issue so I thought I’d share my experience.
A little background:
My team are using Service Fabric to host our applications as containers and as the size of our system continues to grow
having a way of locally deploying pre-built applications has become more of a need to have rather than a nice to have.
Always one to try my hand at some hackery I gave writing a local build and deploy powershell module a go.
All was going swimmingly until my local deployment script stumbled across the following issue:
Unable to Verify connection to Service Fabric cluster.
The local build tools I had written would recursively loop through a list of applications, jump in and out of a few functions
and dynamically load and run more scripts where needed.
So for brevity this is something similar to what I had
Import-Module "$ModuleFolderPath\ServiceFabricSDK.psm1"Write-Host"Establish local cluster connection"[void](Connect-ServiceFabricCluster)(Get-Content"${ENV:PROJECT_PATH}/manifest.json")`
| ConvertFrom-Json`
| ForEach-Object {$project=$_.Name
$version=$_.Value
Write-Host"Deploying ${project} version ${version}"$PublishParameters= @{# lots of parameters}
Publish-NewServiceFabricApplication @PublishParameters
}
When the Publish-NewServiceFabricApplication is called, the script throws the error Unable to Verify connection to Service Fabric cluster.
In fact, the line of code which breaks can be found in the Publish-NewServiceFabricApplication.ps1 file found under
C:\Program Files\Microsoft SDKs\Service Fabric\Tools\PSModule\ServiceFabricSDK.
Scroll down to line 170 ish and you’ll see the script attempt (and fail) to execute the following function
Test-ServiceFabricClusterConnection
This had me stumped for a while as the code I was using to deploy had been largly copied and pasted from the given
Visual Studio deployment template.
After some learning about powershell variable scope and some source code digging it looks like the $clusterConnection
variable is incorrectly scoped.
To fix the issue we just need to amend the code above slightly.
You can imagine the above code repeated 5 or 6 times for various dates and values caused a rather bloated class with lots of similar
core search logic. Code duplication like this is not ideal and I find it can be fairly fragile.
After a bit of searching I didn’t find much guidance for common search logic like this so I decided to hand crank my own!
To start with I created a generic object which encapsulates the property, it’s search value and it’s search operator.
The search criteria model I pass to my repository now has a richer set of properties for searching.
This has also eliminated the repeated use of properties such as nValue and nSearchOperator.
Why am I getting so many merge conflicts when I rebase? This should be so simple!
— Colleague having a bad time
I frequently find myself fixing other people’s Git woes but this one was particularly messy.
If we bring it back to basics, nothing seemed irregular. My buddy created his branch off of
master only a few days prior. He spent a couple days implementing a new feature and prepared
to tidy his history ready for code review.
Wham! Massive. Merge. Hell.
Now the size of the work was reasonably large. Not I’ve changed everything from spaces to tabs large
(although given the chance he would!) but a good 60+ files and a few hundred lines of code large.
As a part of my please leave the place tider than you found it policy, I ask my team to squash
irrelevant Git history, leaving either a single commit or few relevant commits; whichever makes for
easier unpicking in case of a problem. This is why I’m called over.
So we start the diagnosis and sure enough, the merge is hell.
For reference we started with:
$ git rebase master -i
Problematic symptom number 1: not all of the code seems to be there. This means every squashed
commit being played is causing us a tonne of conflicts.
We quickly noticed that the interactive rebase hasn’t included the base commit. Strange. Well
there isn’t many commits to look at so picking the last 5 should do the trick…
$ git rebase HEAD~5
ERROR
Commit abc123 is a merge but no -m option was given.
Interesting. Looking through the branch history highlighted the base commit was a merge commit.
Attempting to interactively rebase on to a preserved merge commit is messing with Git dragons which
don’t want to be messed with.
In fact, this is from the documentation:
-p
--preserve-merges
Recreate merge commits instead of flattening the history by replaying commits a merge
commit introduces. Merge conflict resolutions or manual amendments to merge commits are not preserved.
This uses the --interactive machinery internally, but combining it with the --interactive option
explicitly is generally not a good idea unless you know what you are doing.
There’s a far less complex way achieving the same end result.
We start by finding the common ancestor of our two branches. (my_feature and master).
Ignorance of bandwidth limits on the part of traffic senders can result in bottlenecks over frequency-multiplexed media.
— L Peter Deutsch (Source)
It may seem obvious but how many developers do you know who wouldn’t give a second thought to the amount of bandwidth their systems use.
5 years ago you may have dug deep to get a laptop with sufficient resources to run a few virtual machines.
Year on year we’re seeing bigger and faster memory and bigger and faster disks at more affordable prices.
So why isn’t bandwidth keeping up with the trend? Bandwidth hasn’t grown nearly as quickly.
It’s incredibly common to see network architectures using 1 gigabit eithernet which seems plenty, right?
How many engineers really understand what their 1 gigabit network is really capable of?
Let’s start with the misnomer that 1 gigabit is anything close to 1 gigabyte.
It’s a common misinterpretation and the shared use of giga is almost certainly to blame.
In fact, 1 gigabit is equal to 125 megabytes.
Doesn’t sound quite as plentiful anymore does it?
Let’s see what happens when we introduce a protocol to our network. It would stand to reason that any layer of abstraction would eat into our bandwidth.
At TCP level can we expect to see headers wrap our packets.
These headers allow for reliable transportation of data across our of network.
Speaking of reliability, we should acknowledge packet loss happens.
Sliding window limits the rate at which data is exchanged between sender and receiver and exponential back off are all working against you to limit the usefulness of your bandwidth.
The amount of useful remaining bandwidth is estimated to be around 40%.
That’s approximately 50 megabytes per second of our plentiful 1 gigabit network.
You can imagine that once we begin to add HTTP, HTTPS or encryption into the mix we being to see our bandwidth go from 40% to 30% to 20% and that’s before we begin to talk about inefficient text based serialization such as XML and HTML.
We all want to build scalable systems; nobody wants to be victim to their own successes.
Let’s all acknowledge that the pipes won’t be getting bigger any time soon and begin having sensible design discussions about bandwidth.